|
ABBYY FineReader
|
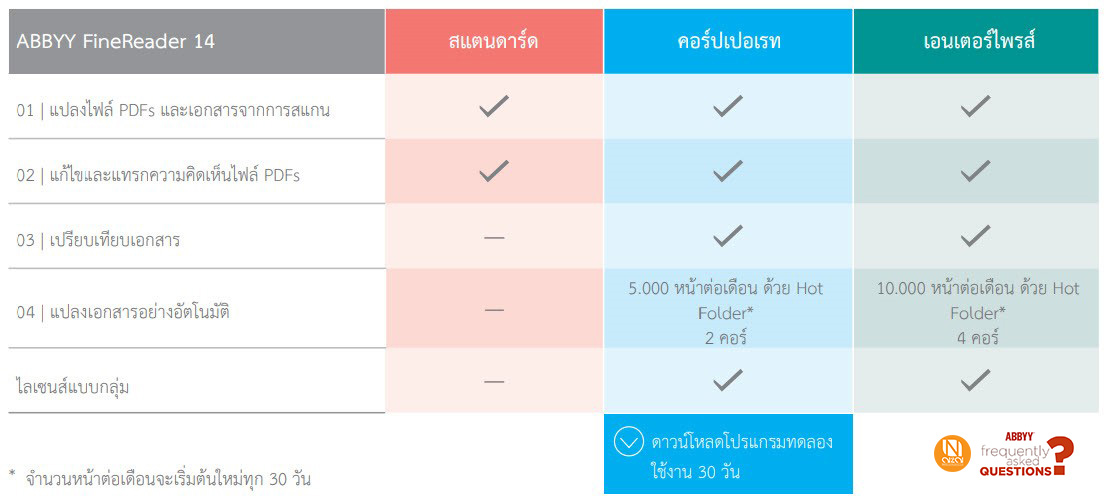
ABBYY FineReader มีกี่รุ่นให้เลือกใช้งาน
|
คุณสมบัติความสามารถพื้นฐานต่าง ๆ ไม่ว่าจะ ด้านการวิเคราะห์โครงสร้างข้อมูลภายในเอกสาร เพื่อระบุว่าบริเวณไหนคือ “ข้อความตัวอักษร”, “รูปภาพ”, “ตาราง” เพื่อให้ทำการแปลงข้อมูลได้อย่างถูกต้อง ด้านการรู้จำภาษาที่รองรับได้มากกว่า 190 ภาษาทั่วโลก ซึ่งรวมถึงการอ่านภาษาไทยได้ถูกต้องแม่นยำที่สุดในท้องตลาด ณ ปัจจุบัน ด้านการส่งข้อมูลผลลัพธ์ที่ได้หลังจากการทำ OCR และแก้ไขข้อมูลให้ถูกต้องแล้ว ผ่านกรอบแก้ไขข้อมูล หรือ Editor ที่มีลักษณะคล้ายๆหน้าต่าง MS Word ไปยังไฟล์นามสกุลที่หลากหลายแล้ว จะเป็นความสามารถที่มีให้ใช้งานอยู่ในทั้ง 3 รุ่นของโปรแกรม ABBYY FineReader แต่สิ่งที่แตกต่างกันอย่างชัดเจนในรุ่นที่เป็น Corporate ต่อตัว Standard นั่นก็คือ ตัว Corporate จะมีคุณสมบัติที่เรียกว่า Hot Folder และ Compare Document มาให้ใช้งาน และสิ่งที่ต่างกันระหว่าง Corporate ต่อ Enterprise (ปัจจุบันจะเรียกว่า Volume Licensing) คือ Hot Folder ในรุ่น Corporate จะทำงานได้ที่ 5,000 แผ่นต่อเดือน และทำงานที่ไม่เกิน 2 คอร์ซีพียู ส่วนรุ่น Enterprise จะทำได้ที่ 10,000 แผ่นต่อเดือน แถมยังทำงานเต็มประสิทธิภาพที่ 4 คอร์ซีพียูด้วย ตามตารางเปรียบเทียบด้านล่าง |
|
 |
ABBYY FineReader มีความแม่นยำขนาดไหน
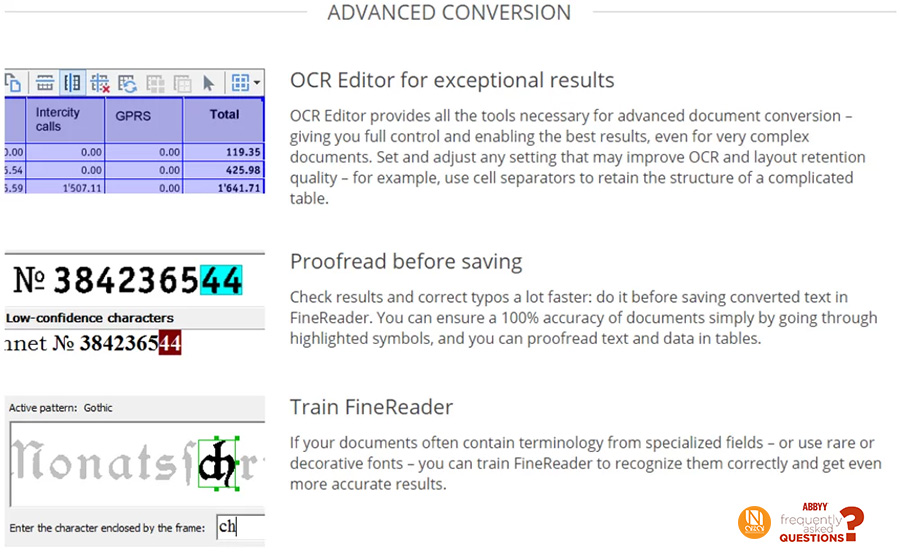
คำถามนี้ถือได้ว่า เป็นคำถามยอดฮิตติดอันดับต้นๆ เมื่อมีการพูดถึงซอฟต์แวร์ที่ “สามารถอ่านภาษาไทยได้” ในการทดสอบภายในห้องทดสอบของ ABBYY โดยมีเงื่อนไขการทดสอบคือ เอกสารที่นำมาทดสอบจะสแกนด้วยโหมด เฉดเทา ความละเอียดในการสแกนอยู่ที่ 300 จุดต่อนิ้ว ตัวอักษรจะอยู่ระหว่าง 12 – 14 จุด หรือ Point และตัวเอกสารที่นำมาสแกนไม่มีข้อมูลรบกวน หรือ Noise เลย จากการทดสอบด้วยเงื่อนไขทั้ง 4 ทำให้ผลลัพธ์ที่ได้หลังจากการทำ OCR จะได้อยู่ระหว่าง 80 -90% เลยทีเดียว ทางแอดมินเองก็ได้ทดสอบกับฟอนต์ที่ราชการไทยใช้งานบ่อยๆ นั้นก็คือ Th Sarabun ก็ได้ % ความถูกต้องที่นาพึ่งพอใจเป็นอย่างยิ่ง
แต่อย่างไรก็ตาม ABBYY ก็ยังมีเครื่องไม้เครื่องมือ ที่แถมมาในชุดของ ABBYY FineReader เพื่อให้การแก้ไข ปรับปรุงข้อมูลมีความสะดวก รวดเร็ว และสามารถนำกลับมาใช้ใหม่ได้ในอนาคต อย่างคุณสมบัติที่เรียกว่า Pattern Training ซึ่งความสามารถนี้ ABBYY อนุญาตให้เราสามารถบอก ABBYY ได้ว่า ตัวอักษรในแต่ละหน้าเอกสาร แต่ละตัวนั้น ตรงกับตัวอักษรอะไรในภาษาไทย และจากนั้นก็บันทึกแบบแผนของรูปตัวอักษรเหล่านั้น เก็บเป็นฐานข้อมูล เพื่อให้สามารถเรียกกลับมาใช้ใหม่ได้ เมื่อพบเจอเอกสารที่มีฟอนต์เหล่านั้นได้ ในอนาคต เพื่อให้การแปลงข้อมูลเกิดความถูกต้องมากยิ่งขึ้นนั่นเอง
ABBYY FineReader รูปภาพที่ถ่ายจากมือถือ ควรปรับภาพอย่างไร
ABBYY FineReader สามารถ OCR เอกสารที่สแกนผ่านเครื่องสแกนเอกสาร และ ไฟล์ภาพที่ได้จากกล้องมือถือได้ แต่จะมีเงื่อนไขเพิ่มเติมสำหรับการถ่ายภาพด้วยกล้องมือถือ เพื่อให้ได้ไฟล์ที่ ABBYY สามารถทำ OCR ได้อย่างมีประสิทธิภาพ คือ
- ความละเอียดในการถ่ายภาพควรมีความละเอียดที่ 5 เมกะพิกเซล ขึ้นไป
- ต้องปิดการใช้งาน Flash เพื่อไม่ให้เกิดแสงสะท้อนบนเอกสารเมื่อถ่ายภาพ
- หากสามารถปรับค่ารูรับแสงได้เอง ก็จะดีมาก เพราะ ค่านี้ทำให้ภาพสว่างขึ้นได้ และมีความคมชัดตลอดแผ่นได้
- หากสามารถกำหนดระยะโฟกัสด้วยมือของผู้ถ่ายได้ ก็จะมั่นใจว่า ภาพที่ถ่ายมาจะมีความคมชัด มากกว่ากการเลือกถ่ายแบบอัตโนมัติให้กล้องกำหนดเอง ซึ่งมีโอกาสที่เอกสารบางหน้าจะหลุดโฟกัสได้
- หากมีระบบต่อต้านการสั่นระหว่างถ่ายภาพ หรือ นำกล้องติดตั้งไว้ที่ขาตั้งกล้อง ก็จะดีมากๆ เพราะ จะไม่เกิดปัญหาการเบลอของเอกสาร
แต่อย่างไรก็ตาม ABBYY ก็ยังมีเครื่องไม้เครื่องมือ ที่แถมมาในชุดของ ABBYY FineReader เพื่อให้การแก้ไข ปรับปรุงคุณภาพของภาพที่มาจากแหล่งต่าง ๆ ให้มีความเหมาะสมต่อการทำ OCR ซึ่งเราสามารถเข้าไปใช้งานได้ที่หน้าต่าง OCR Edition เพิ่มเติมได้