



เทคโนโลยีในการจับภาพ และการแยกประเภทเอกสารของ ABBYY นั้น จะอยู่บนทฤษฎีของความสมบูรณ์, วัตถุประสงค์ และความสามารถในการปรับตัว ที่เลียนแบบวิธีการรับรู้ข้อมูลของมนุษย์ โดยเป็นทฤษฎีพื้นฐานเดียวกันที่สร้างชื่อ และได้รับรางวัลของ ABBYY โดยมาจากเทคโนโลยีของ ABBYY FineReader OCR และ ABBYY FlexiCapture ICR
![]() ลองนึกภาพดูว่า ถ้าคุณจะทำการแยกใบแจ้งหนี้จากเอกสารอื่นๆ ในกอง แล้วต้องการหาข้อมูลที่สำคัญ เช่น เลขที่ใบแจ้งหนี, วันที่, ยอดรวมทั้งหมด, ที่อยู่ของผู้ขาย เป็นต้น คุณจะต้องทำอย่างไร
ลองนึกภาพดูว่า ถ้าคุณจะทำการแยกใบแจ้งหนี้จากเอกสารอื่นๆ ในกอง แล้วต้องการหาข้อมูลที่สำคัญ เช่น เลขที่ใบแจ้งหนี, วันที่, ยอดรวมทั้งหมด, ที่อยู่ของผู้ขาย เป็นต้น คุณจะต้องทำอย่างไร
วิธีที่คุณจะสามารถทำได้นั้น คือ???
คือ การมองหาคำเฉพาะ เช่น “ใบแจ้งหนี้” หรือ “เลขที่ใบแจ้งหนี้” ซึ่งคำเฉพาะเหล่านี้จะช่วยในการระบุว่าเอกสารนี้ คือ ใบแจ้งหนี้ นั่นเอง และขั้นตอนต่อมาก็คือการหาขอบเขตข้อมูล จากประสบการณ์ที่ผ่านมาหรือด้วยตรรกะทั่วไปในการทำงาน คุณจะต้องมองหาหมายเลขของใบแจ้งหนี้, วันที่ และที่อยู่ของผู้ขาย ที่อยู่ด้านบนของเอกสารหน้าแรก และยอดรวมทั้งหมด ที่อยู่ด้านล่างของเอกสารหน้าสุดท้าย ใบแจ้งหนี้นั้น อาจจะมีตัวเลขหลายตำแหน่ง เช่น หมายเลขจัดส่ง, หมายเลขอ้างอิง, หมายเลขลูกค้า หรือ หมายเลขสั่งซื้อ เป็นต้น (อ้างอิงรูปภาพที่ 1) เช่นกันวันที่ก็อาจจะมีหลายตำแหน่ง เช่น วันที่ใบแจ้งหนี้, วันที่สั่งซื้อ หรือวันที่จัดส่ง เป็นต้น หรือแม้กระทั่งยอดค่าจำนวนที่มีหลายตำแหน่งที่อยู่บริเวณใกล้เคียงกัน
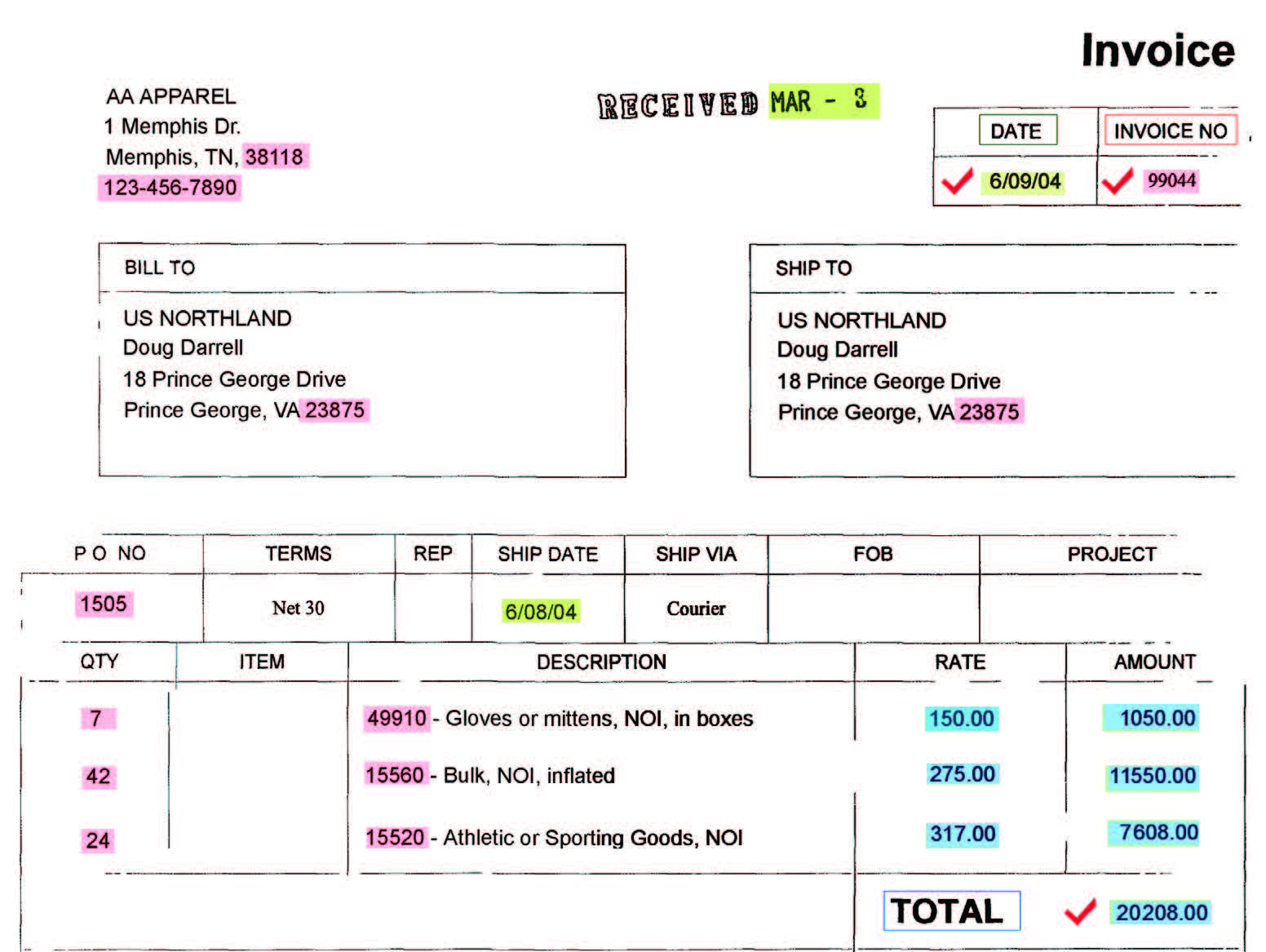 ภาพประกอบที่ 1
ภาพประกอบที่ 1
ซึ่งเราจะสามารถแยกข้อมูลให้ถูกต้องได้อย่างไร?
ด้วยคำสำคัญหรือองค์ประกอบที่อยู่ใกล้เคียงนั้น จะช่วยให้สามารถทำการจำแนกข้อมูลได้ถูกต้อง แต่ในบางกรณีที่ไม่มีคำสำคัญที่จะใช้ คุณจะต้องตรวจสอบเอกสารทั้งหมด เพื่อพิจารณาถึงองค์ประะกอบ และความสัมพันธ์ของตำแหน่งข้อมูลต่างๆ บนเอกสาร
 เทคโนโลยีของ ABBYY FlexiCapture นั้น ใช้หลักการพื้นฐานเหมือนกับของ IPA โดยไม่ได้วิเคราะห์แต่ละข้อมูลแยกออกจากกัน แต่คำนึงถึงความสัมพันธ์ระหว่างข้อมูลทั้งหมด รวมถึงตัวอักขระด้วย แล้วทำการกำหนดคู่ที่ดีที่สุดสำหรับชุดของข้อมูล แน่นอนว่าด้วยความฉลาดและความยืดหยุ่นในการดึงข้อมูลของโปรแกรมจะช่วยให้ค้นหาข้อมูลที่ต้องการได้ทุกที่บนเอกสาร โดยใช้ข้อมูลใดๆ ที่มีอยู่ในการอ้างอิง เช่น เนื้อหาของฟิลด์, ความสัมพันธ์กับข้อมูลอื่นๆ, ขนาดของฟิลด์, เส้นหรือช่องว่างในบริเวณใกล้เคียง เป็นต้น
เทคโนโลยีของ ABBYY FlexiCapture นั้น ใช้หลักการพื้นฐานเหมือนกับของ IPA โดยไม่ได้วิเคราะห์แต่ละข้อมูลแยกออกจากกัน แต่คำนึงถึงความสัมพันธ์ระหว่างข้อมูลทั้งหมด รวมถึงตัวอักขระด้วย แล้วทำการกำหนดคู่ที่ดีที่สุดสำหรับชุดของข้อมูล แน่นอนว่าด้วยความฉลาดและความยืดหยุ่นในการดึงข้อมูลของโปรแกรมจะช่วยให้ค้นหาข้อมูลที่ต้องการได้ทุกที่บนเอกสาร โดยใช้ข้อมูลใดๆ ที่มีอยู่ในการอ้างอิง เช่น เนื้อหาของฟิลด์, ความสัมพันธ์กับข้อมูลอื่นๆ, ขนาดของฟิลด์, เส้นหรือช่องว่างในบริเวณใกล้เคียง เป็นต้น
เทคโนโลยีนั้นสามารถทำงานได้ดี ถึงแม้ว่าจะต้องจัดการกับเอกสารที่มีคุณภาพต่ำ ที่ไม่สามารถทำการรู้จำได้อย่างสามบูรณ์ด้วยความสามารถของ OCR ก็ตาม ตามหลักการแล้ว วิธีของ IPA นั้น แตกต่างจากเทคโนโลยีของ ABBYY FlexiCapture ที่มีการระบบวิเคราะห์ข้อมูลแบบต่อเนื่องและสัมพันธ์กัน โดยระบบดังกล่าวจะตรวจสอบความสัมพันธ์ระหว่างที่พบและองค์ประกอบที่ตามมา แต่ไม่ได้คำนึงถึงความสัมพันธ์ระหว่างข้อมูลอื่นๆ ทั้งหมดที่พบบนเอกสารภาพ ข้อเสียเปรียบหลัก คือ เมื่อโปรแกรมทำการตัดสินใจผิดพลาดในข้อมูลแรก ก็จะส่งให้ไม่สามารถหาข้อมูลอื่นๆ ที่เกี่ยวข้องกันต่อได้ แต่สำหรับ ABBYY FlexiCapture นั้น มีความยืดหยุ่นที่ให้ผลลัพธ์ที่น่าเชื่อถือ ถึงแม้จะเป็นการจับข้อมูลที่โครงสร้างที่ซับซ้อนหรือรูปแบบที่หลากหลายได้
ทฤษฏี IPA?
เทคโนโลยีรู้จำของ ABBYY นั้น ถูกพัฒนาขึ้นโดยอ้างอิงจากทฤษฏีของความสมบูรณ์, วัตถุประสงค์ และความสามารถในการปรับตัว หรือเรียกว่า IPA ซึ่งแตกต่างจากเทคโนโลยีอื่นที่เน้นไปยังการรู้จำรูปแบบ โดยในกระบวนการของการรู้จำนั้น จะอาศัยระบบปัญญาประดิษฐ์ในการสอนคอมพิวเตอร์ให้สามารถทำการวิเคราะห์เอกสารได้ เหมือนอย่างมนุษย์ที่สามารถวิเคราะห์เอกสารนั่นเอง
ว่าด้วยตามทฤษฎีของความสมบูณ์นั้น FlexiCapture มองว่าเอกสารนั้นเป็นข้อมูลชุดเดียวกัน ซึ่งอาจจะประกอบไปด้วยข้อมูลหลากหลายมาอยู่รวมกัน เช่น คำ, เส้น, รูปภาพ และองค์ประกอบอื่นๆ โดยในแต่ละข้อมูลนั้นเมื่อทำการวิเคราะห์แล้วจะเห็นได้ว่ามีความสมบูรณ์อยู่ในตัวเอง หรืออาจต้องใช้หลายข้อมูลรวมกัน ยกตัวอย่างเช่น คำว่า “ที่อยู่” ก็จะประกอบไปด้วย บ้านเลขที่, ถนน, แขวง, เขต และจังหวัด ซึ่งในแต่ละข้อมูลนั้น ก็มีความหมายของตัวเอง แต่ถ้านำข้อมูลเหล่านี้มารวมกลุ่มกันก็ได้ข้อมูลที่เรียกว่า ที่อยู่ นั่นเอง
 ทฤษฎีของวัตถุประสงค์ กล่าวคือ FlexiCapture นั้น ก็มีการกระบวนการคิดคล้ายกับมนุษย์ ก็คือ การสร้างสมมุติฐาน หรือความเป็นไปได้ของข้อมูลที่เราสนใจที่อยู่บนเอกสาร โดยมันจะค้นหาข้อมูลที่เราสนใจจากเอกสารทั้งหมด เช่น เมื่อเราสนใจข้อมูล “วันที่ใบแจ้งหนี้” โปรแกรมก็จะทำการตรวจสอบค้นหาข้อมูลดังกล่าว โดยตั้งสมมุติฐานจากลักษณะ หรือรูปแบบที่เป็น “วันที่” ทั้งหมดที่มีอยู่บนเอกสาร แล้วจากนั้นก็นำมาทำการวิเคราะห์ ถึงความเป็นไปได้ว่าข้อมูลใด เป็นข้อมูลที่เราสนใจ
ทฤษฎีของวัตถุประสงค์ กล่าวคือ FlexiCapture นั้น ก็มีการกระบวนการคิดคล้ายกับมนุษย์ ก็คือ การสร้างสมมุติฐาน หรือความเป็นไปได้ของข้อมูลที่เราสนใจที่อยู่บนเอกสาร โดยมันจะค้นหาข้อมูลที่เราสนใจจากเอกสารทั้งหมด เช่น เมื่อเราสนใจข้อมูล “วันที่ใบแจ้งหนี้” โปรแกรมก็จะทำการตรวจสอบค้นหาข้อมูลดังกล่าว โดยตั้งสมมุติฐานจากลักษณะ หรือรูปแบบที่เป็น “วันที่” ทั้งหมดที่มีอยู่บนเอกสาร แล้วจากนั้นก็นำมาทำการวิเคราะห์ ถึงความเป็นไปได้ว่าข้อมูลใด เป็นข้อมูลที่เราสนใจ
ทฤษฎีของความสามารถในการปรับตัว ว่าด้วยเรื่องของการคำนวนเชิงเรขาคณิตของขอบเขตพื้นที่ข้อมูล กล่าวคือ เป็นการกำหนดค่าหรือรายละเอียดต่างๆ ของข้อมูลที่เราสนใจ เพื่อใช้ในการค้นหา และจับข้อมล ตัวอย่างเช่น เราสนใจข้อมูล “วันที่ใบแจ้งหนี้” เราจำเป็นต้องสร้าง element เพื่อใช้ในการค้นหาและจับข้อมล โดยการกำหนดคำที่ใช้ค้นหา เช่นคำว่า “Date” และกำหนดขอบเขตในการค้นหา เช่น ค้นหาเฉพาะส่วนบนของเอกสารหน้าแรก เป็นต้น เมื่อโปรแกรมทำการประมวลผล ก็จะตรวจสอบค้นหาจากคำ และขอบเขตที่กำหนด โดยมิได้สนใจว่าจะอยู่ตำแหน่งทางด้านซ้าย กลาง หรือขวา เพราะในแต่ละชุดเอกสารนั้น อาจมีตำแหน่งของข้อมูลที่เราสนใจอยู่ไม่เหมือนกัน นั่นเอง
