



 ชุดพัฒนาซอฟต์แวร์ ABBYY FineReader Engine จะช่วยให้นักพัฒนาซอฟต์แวร์สามารถสร้างแอพพลิเคชั่นที่ดึงข้อมูลที่เป็นข้อความออกจากเอกสารกระดาษ, รูปภาพ หรือจากจอแสดงผลได้ OCR SDK ที่ขับเคลื่อนด้วย AI นี้ ทำให้แอปพลิเคชันของคุณมีการจดจำข้อความได้ยอดเยี่ยม, รองรับการแปลงไฟล์ PDF และฟังก์ชันต่างๆเพื่อการจับข้อมูลจากฟอร์มเอกสาร จากนั้นก็แปลงงานสแกน ให้เป็นเอกสาร PDF, Word หรือ Excel ที่ค้นหาได้ และ เข้าถึงข้อมูลบนภาพถ่าย หรือภาพจากหน้าจอคอมพิวเตอร์
ชุดพัฒนาซอฟต์แวร์ ABBYY FineReader Engine จะช่วยให้นักพัฒนาซอฟต์แวร์สามารถสร้างแอพพลิเคชั่นที่ดึงข้อมูลที่เป็นข้อความออกจากเอกสารกระดาษ, รูปภาพ หรือจากจอแสดงผลได้ OCR SDK ที่ขับเคลื่อนด้วย AI นี้ ทำให้แอปพลิเคชันของคุณมีการจดจำข้อความได้ยอดเยี่ยม, รองรับการแปลงไฟล์ PDF และฟังก์ชันต่างๆเพื่อการจับข้อมูลจากฟอร์มเอกสาร จากนั้นก็แปลงงานสแกน ให้เป็นเอกสาร PDF, Word หรือ Excel ที่ค้นหาได้ และ เข้าถึงข้อมูลบนภาพถ่าย หรือภาพจากหน้าจอคอมพิวเตอร์
OverviewBenefitsTutorialsSpecifications
มีให้พร้อมใช้งานสำหรับแพลตฟอร์ม Windows, Linux, Mac OS และแบบฝังตัว
หรือให้อยู่บน On-Premises หรือ ใน Cloud ก็ได้
 |
 |
 |
|
ความแม่นยำด้าน OCR สูง มอบคุณภาพงาน OCR ที่โดดเด่นให้กับลูกค้าของคุณด้วย ABBYY FineReader ผู้ให้บริการชั้นนำเกี่ยวกับระบบ ECM, การทำภาพเอกสาร และโซลูชั่นการจับภาพ, โซลูชั่น RPA และ ผู้ผลิตเครื่องสแกน และ MFP ต่างก็เชื่อมั่นในเทคโนโลยี OCR จาก ABBYY |
เพิ่มพูนมูลค่า ขยายโซลูชั่นของคุณ ABBYY FineReader Engine ช่วยให้ซอฟต์แวร์ของคุณแปลงไลบรารี่ TIFF ให้เป็นไฟล์ PDF, PDF / A, Word หรือรูปแบบอื่น ๆ และแยกค่าฟิลด์ได้อย่างแม่นยำ มันสามารถพัฒนาบน Windows, Linux หรือ Mac และ นำซอฟต์แวร์ของคุณไปไว้บน Cloud หรือ บน VM ก็ได้ |
นำสู่ตลาดในเวลาที่รวดเร็วกว่า ด้วย API อันทรงพลังของชุดเครื่องมือ OCR นี้ ที่มีประสิทธิภาพ ทำให้คุณอยู่เหนือการแข่งขัน และได้รับโซลูชั่น OCR ระดับพรีเมียมเพื่อป้อนเข้าสู่ตลาดได้อย่างรวดเร็วมากขึ้น มีการรวมคุณสมบัติ OCR ระดับโลก ใช้งานได้อย่างง่ายดาย ด้วยความช่วยเหลือของเครื่องมือ, พารามิเตอร์ต่างๆ, ตัวอย่างโค้ดมากมาย และองค์ประกอบอื่น ๆ |
คุณสมบัติที่โดดเด่น
 ชุดเทคโนโลยีด้านการจดจำข้อมูลที่มีมาครบ ชุดเทคโนโลยีด้านการจดจำข้อมูลที่มีมาครบ
ด้วยการรวมชุดเครื่องมือ OCR แอปพลิเคชันต่างๆ สามารถแยกข้อความที่มาจากการพิมพ์ได้มากกว่า 200 ภาษาทั่วโลก รวมถึงข้อความที่เขียนด้วยมือ, กรอบเช็คข้อมูล และบาร์โค้ด ก็สามารถจับออกมาได้ |
 เครื่องมือประมวลผลไฟล์ PDF ที่ทรงประสิทธิภาพ เครื่องมือประมวลผลไฟล์ PDF ที่ทรงประสิทธิภาพ
APIs อเนกประสงค์ จะช่วยให้การประมวลผล PDF หลากหลายประเภท และการแปลงเอกสารที่สแกน ไม่ว่าจะนาสกุล TIFF, JPEG หรือ PDF ชนิดรูปภาพ ให้เป็นไฟล์ PDF และ PDF / A ที่ค้นหาเนื้อความในเอกสารได้ |
 ปัญญาประดิษฐ์ และการเรียนรู้ของเครื่อง ปัญญาประดิษฐ์ และการเรียนรู้ของเครื่อง
AI, ML และเทคโนโลยีขั้นสูงอื่น ๆ สามารถให้ความแม่นยำในการจดจำที่ยอดเยี่ยมสำหรับเอกสารหลายภาษา และส่งมอบเอกสารผลลัพธ์ที่ค้นหา กับแก้ไขได้ ซึ่งจะสอดคล้องกับเนื้อหาของเอกสารต้นฉบับเอกสารเหล่านั้น |
 รองรับซีพียูหลายคอร์, คลาวด์ และ เครื่องจักรเสมือน รองรับซีพียูหลายคอร์, คลาวด์ และ เครื่องจักรเสมือน
รองรับการประมวลผลเอกสารในแบบเธรดขนานบน CPU แบบหลายคอร์ การนำไปใช้งาน สามารถใช้ในระบบคลาวด์ และสภาพแวดล้อมเสมือนจริงได้ รับประกันการประมวลผลที่รวดเร็ว, มีควายืดหยุ่น และปรับขนาดได้ในอนาคต |
 ABBYY FineReader Engine – เครื่องมือ OCR SDK ที่ครอบจักรวาล
ABBYY FineReader Engine – เครื่องมือ OCR SDK ที่ครอบจักรวาล
เรียนรู้ว่าชุดพัฒนาซอฟต์แวร์ ABBYY FineReader Engine สามารถเพิ่มคุณค่าให้กับแอปพลิเคชันของคุณได้อย่างไร
![]() ABBYY FineReader Engine Brochure
ABBYY FineReader Engine Brochure
เรื่องราวของลูกค้า
 |
 |
 |
| Volkswagen Corporation ได้ผนวกรวม ABBYY OCR หลายภาษา ไว้ในระบบวิชันซิสเต็มของพวกเขา เพื่อทดสอบระบบ Infotainment ในรถยนต์โดยอัตโนมัติ | Canon ได้รวมความสามารถด้านการจดจำข้อความของ ABBYY ไว้ในระบบการจัดการเอกสารของตนเอง เพื่อสร้างเอกสารที่ค้นหาได้ในระหว่างกระบวนการสแกน | Athenahealth ผู้ให้บริการด้านการดูแลสุขภาพของสหรัฐอเมริกาใช้ ABBYY OCR เพื่อทำสำเนาดิจิตอลเป็นล้าน ๆ หน้าต่อสัปดาห์ เพื่อผลักดันให้เกิดการดูแลผู้ป่วยอย่างมีประสิทธิภาพ |
 |
 |
 |
| EBOOK
พร้อมไหมกับปัญญาดิจิตอล? เรียนรู้ว่าเทคโนโลยีที่ใช้ AI เพื่อขยายมูลค่าของผลิตภัณฑ์ซอฟต์แวร์อย่างไร |
WEBINAR
บูรณาการฟังก์ชั่น OCR ที่ใช้ AI เข้ากับแอปพลิเคชันของคุณ เรียนรู้เกี่ยวกับชุดเครื่องมือที่ใช้งานง่ายซึ่งรวมงาน OCR, การแปลง PDF, การจัดหมวดหมู่เอกสารและฟังก์ชันการจับข้อมูล |
WHITE PAPER
ทดสอบ OCR SDK อย่างไร? คู่มือนี้ จะอธิบายประเด็นสำคัญๆ สำหรับนักพัฒนาเพื่อใช้ดูการเตรียมภาพ, ความแม่นยำของงาน ocr และ การวัดความเร็ว, การลดขนาดของไฟล์ sdk แบบกระจายและอื่น ๆ |
ประโยชน์ที่ได้รับ
ไม่ว่าคุณจะเป็นผู้จำหน่ายซอฟต์แวร์, ผู้พัฒนาระบบ หรือ บริษัทองค์กรที่พัฒนาระบบไอทีของคุณเอง ABBYY OCR SDK จะช่วยคุณสร้างแอปพลิเคชันการประมวลผลข้อความ และข้อมูลภาพที่มีความแม่นยำสูง มาดูกันซิว่าคุณจะได้ประโยชน์จากการผนวกรวม ABBYY FineReader Engine เข้ากับแอปพลิเคชันของคุณอย่างไร
|
เพิ่มประสิทธิภาพการทำงานของซอฟต์แวร์ของคุณ และความคุ้มค่า ด้วย ABBYY OCR แอปพลิเคชันของคุณสามารถแปลงกระดาษ, ไฟล์ TIFF และ JPEG ให้เป็นไฟล์ PDF และ PDF/A ที่ซึ่งสามารถค้นหาข้อมูลภายในได้ และก็ยังสามารถดึงข้อมูล หรือข้อความจากภาพถ่าย หรือภาพจากหน้าจอคอมได้อีกด้วย การเพิ่มฟังก์ชั่นใหม่ได้เพิ่มมูลค่าให้กับระบบของคุณ – และช่วยให้ลูกค้าของคุณเกิดประสิทธิภาพในงานมากขึ้น |
 |
|
 |
สร้างความประทับใจให้ลูกค้าด้วย OCR ที่แม่นยำที่สุด
ประหยัดเวลาของลูกค้า ด้วยการนำเสนอระบบที่มี OCR สามารถจับแยกข้อความด้วยความแม่นยำสูงสุด มีความต้องการแก้ไขข้อผิดพลาดน้อยที่สุด ซึ่งจะทำให้เกิดความประทับใจต่อผู้ใช้งานระบบ ผู้ให้บริการซอฟต์แวร์ชั้นนำ และผู้ผลิตฮาร์ดแวร์ ก็ได้ใช้เทคโนโลยี OCR ระดับพรีเมี่ยมของ ABBYY นี้ในผลิตภัณฑ์ต่างๆของตน |
|
|
เร่งผลผลิตคุณออกสู่ตลาดได้เร็วยิ่งขึ้น การรวมชุดเครื่องมือ ABBYY OCR และใช้ประโยชน์จากชุดคำสั่ง APIs ที่มีเอกสารอธิบายอย่างครบถ้วน, ตัวอย่างโปรแกรม, โปรไฟล์การประมวลผลที่ดีที่สุด, ส่วนประกอบส่วนติดต่อกับผู้ใช้งาน และ การให้ความช่วยเหลือจากผู้เชี่ยวชาญทางเทคนิคของ ABBYY จะช่วยให้คุณลดระยะเวลาในการพัฒนาระบบงาน – ช่วยให้คุณนำซอฟต์แวร์ของคุณออกสู่ตลาดได้เร็วขึ้น |
 |
|
 |
เสนอแอพพลิเคชั่นสำหรับตลาดต่างประเทศ
ด้วยความพร้อมใช้งานของชุดคำสั่งทั้งงานแบบ OCR และ ICR รองรับได้หลากหลายภาษา ซึ่งสามารถนำมาใช้งานพร้อมๆกันได้ ทำให้ซอฟต์แวร์ของคุณเหมาะอย่างยิ่งสำหรับลูกค้าที่ประมวลผลเอกสารหลายภาษา หรือองค์กรระดับโลกที่ดำเนินงานในตลาดต่างประเทศ |
|
|
สร้างซอฟต์แวร์เอนกประสงค์สำหรับหลายแพลตฟอร์ม สร้างแอปพลิเคชันสำหรับเดสก์ท็อป หรือเซิร์ฟเวอร์ ให้ทำงานบน Windows, Linux หรือ Mac และก็ยังนำไปทำงานบนระบบ Colud หรือ ทำงานภายใต้ VM ก็สามารถเป็นไปได้ คุณสมบัติ OCR ที่หลากหลายสามารถเพิ่มคุณค่าให้กับแอปพลิเคชันในสายงานต่างๆ เช่น DMS, ERP, RPA, ประกัน, ธนาคาร, การดูแลสุขภาพ, กฎหมาย และ ระบบตรวจสอบทางกายภาพของผลิตภัณฑ์ |
 |
วิดีโอการสอนเพื่อการเริ่มต้นแสนง่าย
ลองชมวิดีโอสั้น ๆ เหล่านี้เพื่อศึกษาถึงวิธีการรวม ABBYY FineReader Engine เข้ากับแอปพลิเคชันของคุณ ดูว่าโปรไฟล์การประมวลผลที่แตกต่างกันนั้น จะช่วยให้คุณได้รับผลการรู้จำข้อมูลที่ดีที่สุดได้อย่างง่ายดายอย่างไร
 |
 |
|
เริ่มต้นกับ FineReader Engine และการประมวลผลเอกสาร วิดีโอนี้จะแนะนำคุณผ่านตัวอย่างจากซอร์สโค้ด C ++ ตัวอย่างนี้แสดงให้เห็นถึงวิธีการเริ่มต้น FineReader Engine และวิธีการจดจำเอกสารที่มีพารามิเตอร์ต่างกัน สำหรับการประมวลผลและส่งออก |
ใช้ส่วนประกอบ UI เพื่อสร้าง GUI ของคุณเอง และทดสอบพารามิเตอร์ต่างๆเพื่องานการรู้จำ ในวิดีโอนี้คุณจะได้เรียนรู้วิธีสร้าง GUI ของแอปพลิเคชันของคุณโดยใช้ส่วนประกอบ UI ที่มีให้ในไลบรารีตัวอย่างโค้ดของ SDK นอกจากนี้ คุณจะได้เรียนรู้วิธีการใช้แอพตัวอย่างส่วนประกอบภาพ เพื่อค้นหาโปรไฟล์การประมวลผลที่เหมาะสมสำหรับงานการจดจำข้อมูลของคุณ |

|
ABBYY FineReader Engine 12 มีให้เลือกใช้งาน 3 เวอร์ชั่นดังนี้: ABBYY FineReader Engine 12 for Windows ABBYY FineReader Engine 12 for Linux ABBYY FineReader Engine 12 for Mac |
System requirements
Supported recognition languages
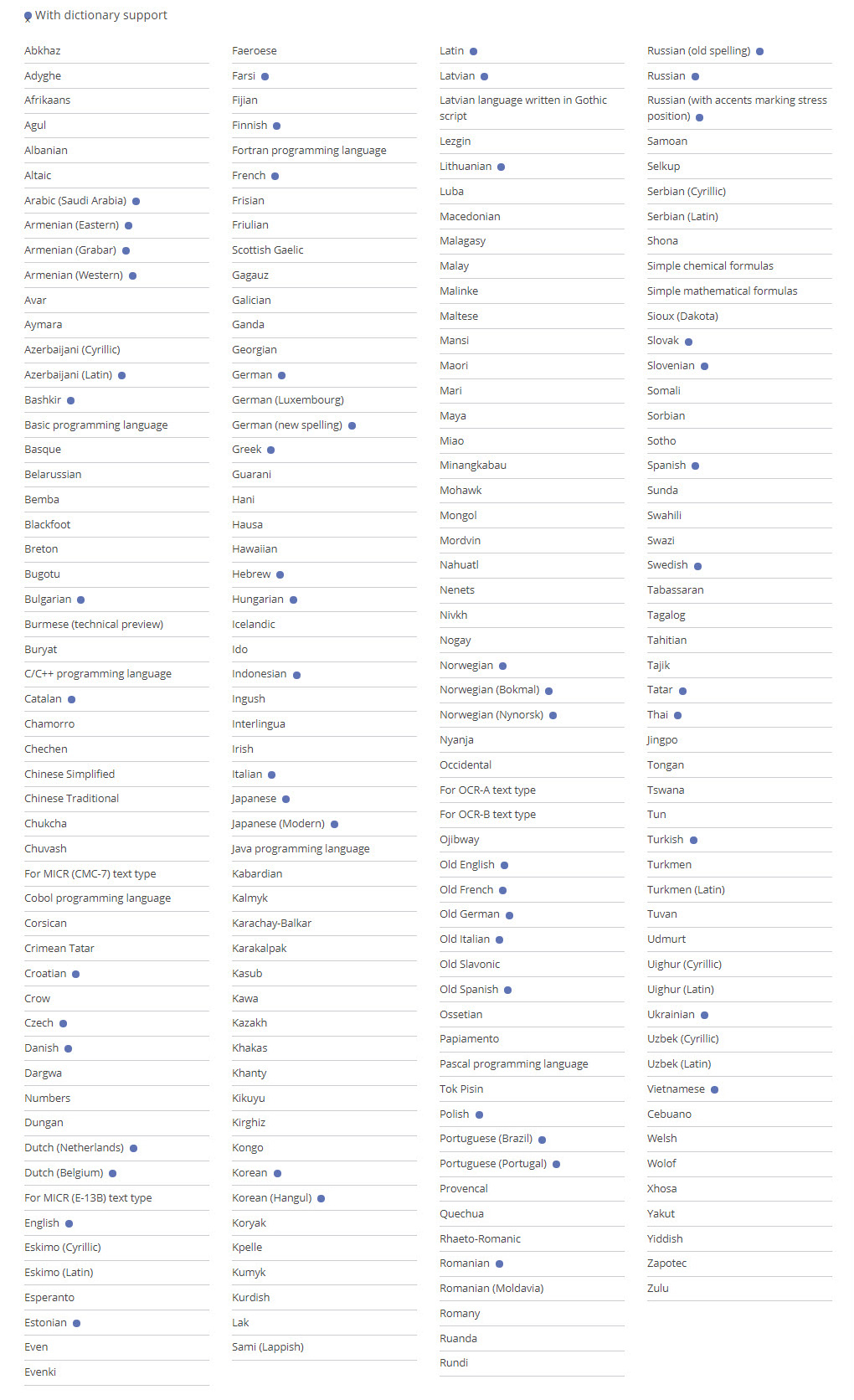
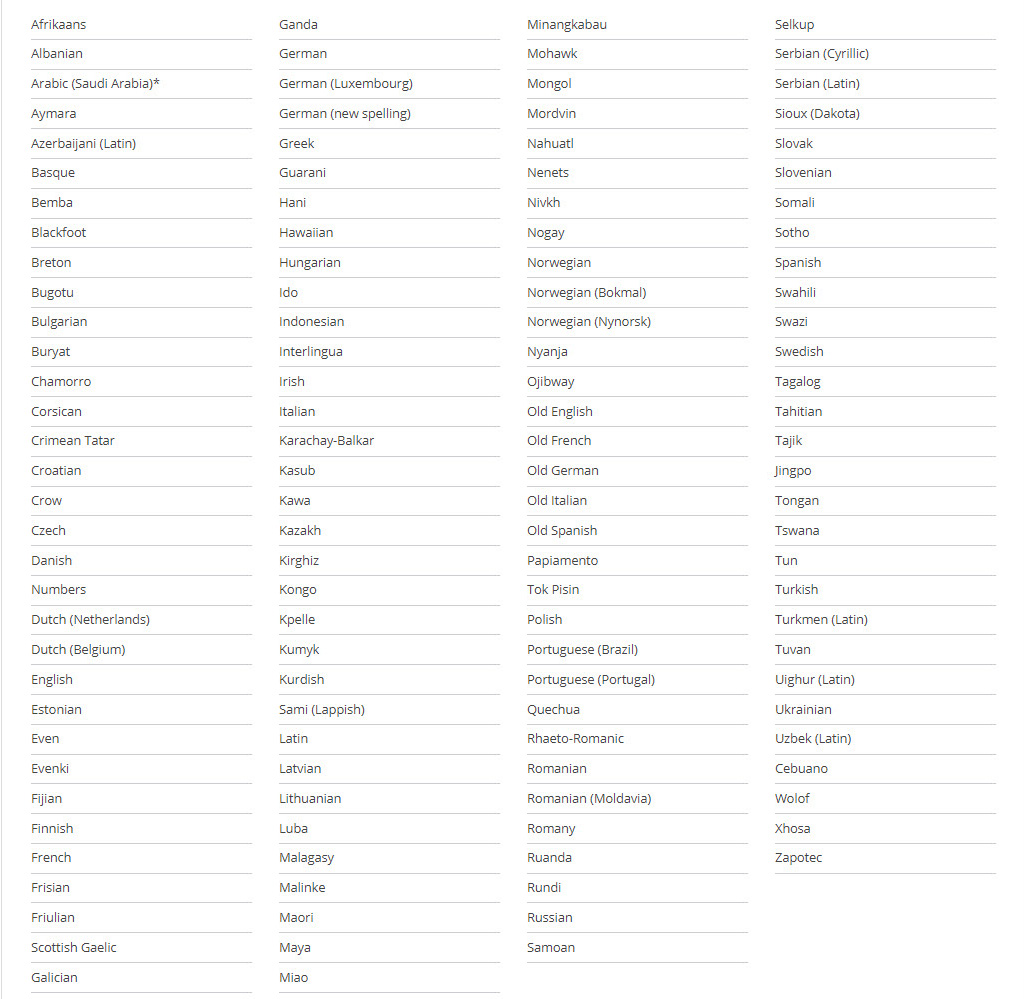
ABBYY FineReader Engine 12 provides support for the highest number of recognition languages on the market. It offers recognition of languages with Latin, Cyrillic, Greek or Armenian characters, as well as Arabic, Burmese (technical preview), Farsi, Hebrew, Chinese, Japanese, Korean, Russian, Thai and other languages. To further increase the recognition accuracy, integrated dictionaries are provided for many languages. To increase recognition of unusual words and untypical fonts, a small integrated utility can be used for implementing own dictionaries and creating own character patterns.
In addition, the SDK provides recognition of historic documents printed between 17th and 19th century in English, French, German, Italian and Spanish, recognition of artificial languages (Esperanto, Interlingua, Ido and Occidental) recognition of programming languages (Basic, C/C++, COBOL, Fortran, JAVA, and Pascal), simple chemical formulas and standard digits.
Up to 210 OCR languages
126 ICR languages
28 BCR language

Languages for interaction with the user
Message boxes such as error messages, tips and warnings are available in English, Bulgarian, Czech, Chinese (PRC and Taiwan), Danish, Dutch, Estonian, French, German, Greek, Hungarian, Italian, Japanese, Korean, Polish, Portuguese (Brazil), Russian, Slovak, Spanish, Swedish, Turkish, and Ukrainian.
Supported Office input formats
ABBYY FineReader Engine can open documents created in the following formats:
- Text formats: .doc, .docx, .rtf, .htm / .html, .txt, .odt
- Table formats: .xls, .xlsx, .ods
- Presentation formats: .ppt, .pptx, .odp
- Digitally created PDFs: .pdf
Supported document saving formats
ABBYY FineReader Engine can save the recognized text in the following formats:
|
|
Supported barcode types
ABBYY FineReader Engine recognizes following types of barcodes:
- 1D: Codabar, Code 128, Code 39, Code 93, Code 32, EAN 8 and 13, Full ASCII Code 39, GS1-128, IATA 2 of 5, Industrial 2 of 5, Interleaved 2 of 5, Intelligent Mail (a.k.a USPS 4-CB), Matrix 2 of 5, Patch, PostNet, UPC-A, UPC-E (in addition to the above list, following 1D barcodes are available in the version for Windows: KIX, Royal Mail 4-State (RM4SCC), Australia Post 4-State).
- 2D: Aztec, Data Matrix, MaxiCode, PDF 417, QR Code.
Extraction of data from Machine Readable Zones (MRZ)
ABBYY FineReader Engine can detect a machine-readable zone on the image of an ID or travel document and extract data that is encoded in accordance with the ICAO Document 9303.
FineReader Engine will extract machine-readable data from both types of MRZ fields:
- 2 lines
- 3 lines
Additional information that can be extracted:
|
|
|
Where available, the Engine extracts check digits of each value. To provide information about the quality of data extraction, it uses Boolean value that specifies whether the checksum over the individual value matches the check digit.
Optical mark recognition
ABBYY FineReader Engine recognizes simple checkmarks, grouped checkmarks, model checkmarks and checkmarks that were corrected by hand:
- Checkmarks in a square frame
- Checkmarks against the empty background
- Non-standard checkmarks (this type of checkmarks requires prior training)
For additional technical information, please refer to ABBYY.technology or consult the ABBYY FineReader Engine Help file.